























ANSYS BLOG
May 11, 2022
Ansys FluentのためにGPUのフルパワーを解き放つ(パート1)
職場からの帰宅、ニューヨークからロンドンへのフライト、会社がアップグレードしようとしないオフィスの古いコーヒーメーカー・・・。数値流体力学(CFD: Computational Fluid Dynamics)シミュレーションと同様に、これらはすべてスピードアップから恩恵を受けます。
長年にわたり、CFDシミュレーションの加速で重要な役割を果たすものの1つとしてハイパフォーマンスコンピューティング(HPC: High-Performance Computing)があり、さらに近年になって、これはグラフィックスプロセッシングユニット(GPU: Graphics Processing Unit)に拡大されました。
CFDの世界でGPUを活用することは、新しい概念ではありません。GPUは、かなり長い間CFDアクセラレーターとして使用されており、Ansys Fluentでも2014年以来使用されています。ただし、実際に得られる局所的な加速は問題によって異なります。結局、コードの一部がGPU用に最適化されていない場合、全体的なスピードアップが抑制されます。そのため、ここでは、CFDシミュレーションが複数のGPU上でネイティブに実行されたときのGPUの潜在力をお見せしたいと思います。
これは、当社のブログシリーズ「Ansys FluentのためにGPUのフルパワーを解き放つ」の第1弾です。このシリーズでは、シミュレーション時間、ハードウェアコスト、電力消費の削減にGPUがいかに役立つかについて説明します。この第1弾では、層流と乱流の問題をいくつか取り上げます。シリーズが進むにつれて、物理モデリングの機能についても説明します。
自動車の外部空力シミュレーションを32倍にスピードアップ
最初の例として、自動車の外部空力シミュレーションを見てみましょう。これはごく短時間で非常に大きくなる可能性があり、一般的には3億セルを超えます。このサイズのシミュレーションを実行するには、数千~数万コアと、数日(場合によっては数週間)の計算時間が必要となります。シミュレーション時間を数週間から数日、または数日から数時間に短縮し、同時に電力消費も大幅に削減できる方法があるとしたらどうでしょうか。それがあるのです。そしてそれは、こうしたシミュレーションを完全にGPU上で実行するという方法です。
持続可能性は自動車業界における重要な懸念事項であり、世界中の政府機関が厳格な規制を整備しています。これらの規制を満たすまたは超えるように自動車メーカーが評価してきた領域には以下が含まれます。
- 空力の改善
- 排出量削減
- 代替燃料の使用
- ハイブリッドおよび電気のパワートレインオプションの開発
しかし、持続可能性の取り組みは、最終製品(この場合は自動車)の運用に限定するのではなく、製品の設計プロセスにも拡大する必要があります。これにはシミュレーションが含まれますが、Ansysではシミュレーション中に消費される電力量を削減したいと考えています。

自動車の外部空力シミュレーションは完全にGPU上で実行することによってスピードアップ可能
ここに示すシミュレーションでは、Fluentを使用して、CPUとGPUのさまざまな構成でベンチマークのDrivAerモデルを実行し、パフォーマンスを比較しました。その結果、単一のNVIDIA A100 GPUが、80コアのIntel® Xeon® Platinum 8380を含むクラスターより5倍高いパフォーマンスを達成したことがわかりました。NVIDIA A100 GPUを8個にスケールアップすれば、シミュレーションは30倍以上スピードアップできます。
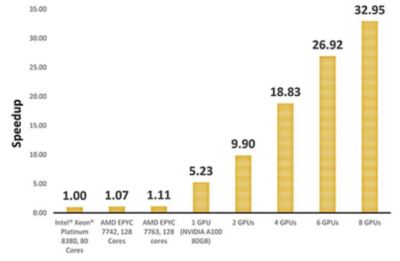
GPU活用時の自動車外部空力シミュレーションのスピードアップ
より短時間で結果が得られれば、お客様の効率は向上しますが、それでは終わりません。このようなシミュレーションの実行に必要な電力を大幅に削減することにより、お客様の電気料金を削減する(同時に地球を助ける)こともできます。
1024コアのIntel® Xeon® Gold 6242を含むCPUクラスターの電力消費量を見ると、それは9600Wでした。NVIDIA® V100 GPUが6個のサーバーと比較すると、その電力消費量は4分の1の2400Wまで削減されました。
これらのベンチマーク結果は、NVIDIA® V100 GPUが6個のサーバーを選ぶ企業が、同等のHPCクラスターと比較して電力消費を4分の1に削減できることを示しています。しかもこれは、サーバールームを涼しく保つための冷房コストの削減は考慮していません。
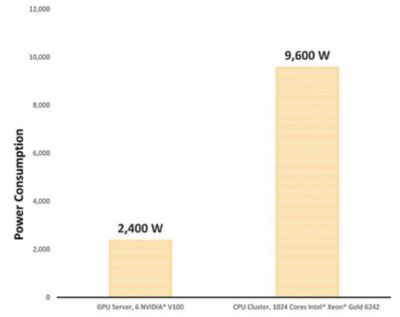
GPUサーバーを使用した場合の電力消費削減
ネイティブのGPUソルバーでシミュレーションを実行することは、会社の持続可能性の取り組みにおいても、結果の待ち時間の短縮においても、直ちに大きな影響が出る可能性があります。しかも、結果なら何でもよいというわけではなく、信頼できる結果なのです。過去40年以上にわたって、Fluentは広範囲のアプリケーションで広く検証されており、業界をリードする精度で知られています。Fluent内で利用可能なCPUとマルチGPUソルバーはいずれも同じ離散化方法と数値解析法を基に構築されており、実質的に同一の結果をユーザーに提供します。
以下の2つの標準的なケースは、層流と乱流レジームから原理をシミュレーションする、確立されたCFD検証です。いずれのケースも、GPU上でネイティブに解析した場合に得られる精度について詳細に説明しています。
球を越える層流
球を越える流れの実験研究や数値研究に関する文献は豊富にあり、外部空力検証の基本的なベンチマークの役割を果たしています。この最初のテストでは、レイノルズ数が100に等しく、流体が球を避けて進み、円筒の背後に時不変の渦構造を形成する層流条件を選択しました。文献で提案されている抗力の相関式を使用して、CFDの結果を実験データと比較します。
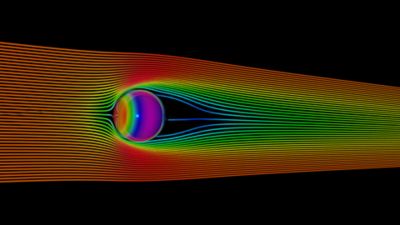
球を越える層流の速度流線と圧力分布のベンチマーク
表1に示すように、ネイティブのGPU実装は、誤差率わずか-0.252%で抗力係数を非常に正確に計算します。

表1. 抗力係数(Cd)の比較
後方に面したステップ
後方に面したステップは、乱流モデルの実装をテストするために使用される標準的な問題です。単純に見える構成には、それが示す物理特性が豊富に含まれています。このテストのために、VogelとEaton2による実験のセットアップを、流入速度2.3176m/sで再作成しました。さまざまな平面におけるチャネルの長さ方向の速度プロファイルを、公表された実験データと比較することにより、CFDコードがテストに加えられます。

後方に面したステップの速度ベクトル
CPU上で解析すると、Fluentは実験結果3、4で良好な妥当性を示しました。この同じ問題をネイティブのマルチGPUソルバーで解析すると、以下に示すように、実質的に同一の結果が得られます。これは、Fluentで利用可能なCPUとGPUがいずれも同じ離散化方法と数値解析法を基に構築されているからです。
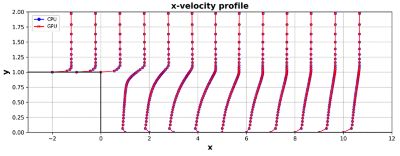
CPUとGPUで解析した場合の後方に面したステップの速度プロファイルの結果
すべてのメッシュタイプを受け入れる非構造化有限体積ナビエ・ストークスソルバーの、このネイティブのマルチGPU実装は、実に斬新であり、精度を落とすことなくCFDの新しい基準を設定します。問題に対してGPUの潜在力を利用することによって得られる大幅なスピードアップをご覧いただきたい場合は、今すぐお問い合わせください。
References
- Turton, R.; and Levenspiel, O., A short note on the drag correlation for spheres, Powder Technol., 47, 83-86, 1986
- Vogel J.C., and Eaton, J. K. (1985) Combined heat transfer and fluid dynamic measurements downstream of a backwards-facing step. J. Heat Transfer 107, 922-929.
- Smirnov, Evgueni & Smirnovsky, Alexander & Shchur, Nikolai & Zaitsev, Dmitri & Smirnov, P. (2018). Comparison of RANS and IDDES solutions for turbulent flow and heat transfer past a backward-facing step. Heat and Mass Transfer. 54. 10.1007/s00231-017-2207-0
- Banait H., Bais A., Khondekar K., Choudhary R., Bhambere M.B. (2020). Numerical Simulation of Fluid Flow over a Modified Backward Facing Step using CFD. International Research Journal of Engineering and Technology. Volume 7, Issue 9