























ANSYS BLOG
March 14, 2019
How to Use Parallel Processing to Generate a 3D Mesh for CFD on an HPC
The scale of computational fluid dynamics (CFD) simulations has grown for decades as users aim to learn more about the performance of their designs under various conditions.
This trend calls for a larger 3D mesh, which poses two challenges: a longer wall clock time and a larger computational load.
While CFD solver technology has taken advantage of parallel processing and high-performance computing (HPC), 3D mesh generation has primarily been a serial process.
Once a 3D mesh is available, parallel CFD solvers can distribute and balance the computational loads across the HPC cluster.
Engineers can now use parallel HPC
to produce a CFD 3D mesh.
In just under two hours, an HPC cluster can solve a massive simulation depicting the takeoff on an aircraft. In fact, solvers are so fast that meshing tends to dominate the wall clock time for a CFD simulation.
With Ansys Fluent, however, engineers can now produce a 3D mesh using parallel processing, reducing the simulation time considerably.
Large CFD Meshes No Longer Require a Lot of Memory
Fluent has taken many strides to speed up the meshing process in the last year. For instance, engineers can use the task-based, watertight geometry workflow to mesh real-life industrial cases with little training.

Meshing an F1 car on a single core required 307 GB of RAM. When the same mesh
was run on a 16-core cluster, the RAM requirement for each core
dropped to 37 GB or less.
The next natural step in meshing speedup is to move from serial to parallel processing.
However, speed is not the only thing limiting the use of large meshes. Historically, a lot of RAM has been required to create these meshes.
For instance, meshing the geometry on a single core can overwhelm that core’s RAM with a few hundred million cells. However, meshes are starting to regularly cross the one billion cell mark.
Users who generate these large meshes on a single core generally need an expensive amount of RAM in addition to the HPC cluster that is required to solve the simulation.
Parallel meshing, however, distributes the problem across multiple cores, and each core has its own set of RAM. When the meshing is done on multiple cores, the RAM requirement per core is reduced. This opens up the use of large 3D meshes to more Ansys users.
How Fluent Generates a 3D Mesh for CFD Using Parallel Processing
Traditionally, parallel meshing has been restricted to methods where partitions are pre-meshed or when both the surface and volume are meshed together. These methods can produce sub-optimal meshes that have low scalability and can miss key features in the geometry.
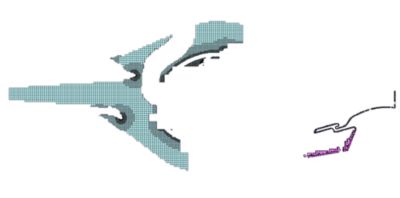
The mesh is generated using parallel processing — each color depicts the parts
of the mesh created by one process. All the Fluent processes work
together to fill the live fluid/solid space.
Fluent’s Mosaic-enabled poly-hexcore algorithm has proven itself for its geometric fidelity, mesh quality, cell count and solver speed. It was only natural to expand the Mosaic meshing technology to include distributed parallel volume meshing.
As a result, the Ansys 2019 R1 version of Fluent introduces a distributed parallel algorithm for all stages of the poly-hexcore volume meshing. This means that the viscous boundary layer, Cartesian core and a polyhedral glue that connects the two are all meshed using parallel processing.
Fluent uses a patent-pending algorithm that sets up adaptive partition interfaces which change multiple times during the overall meshing process. This ensures that the load is balanced and that there are no artificial constraints when meshing elements.
These pliable partitions also ensure that:
- No sliver spaces are formed between interfaces or geometry surfaces.
- Conformal meshes are produced with high accuracy.
- Surface meshes are not altered for the purpose of parallel meshing.
How to Create a 3D Mesh for CFD Using Parallel Processing and HPC
Fluent’s algorithm requires no special preparation of the surface mesh and requires no special tricks by the user.
Just start Fluent in parallel mode. Then, in the volume meshing task, choose the "Enable Parallel Meshing" option for poly-hexcore meshing.
And don’t worry about HPC licenses — parallel meshing doesn’t require any.
Before its release, the algorithm was validated on several industrial models. The meshing process had a consistent speed up around 5x to 11x when running on 64 cores.
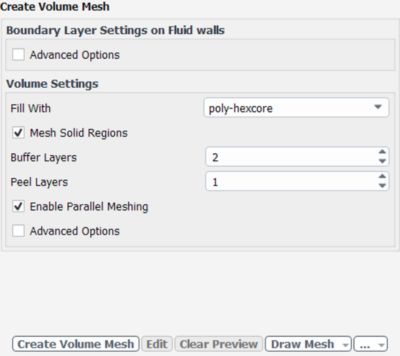
Fluent users can easily access parallel meshing without an HPC license.
So, what does this mean for Ansys users? It means they can address many more design variants in a given timeline. This can ultimately lead to more optimal designs.
For applications requiring massive meshes, it means getting an answer to a design question on the same day.
Furthermore, such applications may have been out of reach to some due to hardware restrictions. Suddenly, this may no longer be the case.
To learn more about meshing, read about Ansys’ Mosaic meshing technology.