























ANSYS BLOG
June 30, 2022
Ansys Fluent용 GPU의 전체 성능 활용, 파트 2
각 작업에 몇 분, 몇 시간 또는 며칠을 절약할 수 있다면 일년 내내 절약할 수 있는 시간을 상상해 보십시오. Ansys Fluent GPU 솔버는 전산유체역학(CFD) 시뮬레이션에서 계산 시간을 줄이는 솔루션을 제공할 수 있습니다.
10만 셀 모델을 계산하든 1억 셀 모델을 계산하든, 시뮬레이션 시간을 줄이기 위한 전통적인 접근 방식은 많은 CPU를 통해 계산하는 것입니다. 최근 몇 년 동안 주목받고 있는 또 다른 접근 방식은 그래픽 처리 장치 또는 GPU를 사용하는 것입니다. 이는 CPU 솔루션의 일부를 GPU로 전달하여 전체 솔루션 시간을 단축하며 시작되었으며, 이를 GPU로의 오프로딩이라고 합니다.
우리는 2014년에 Ansys Fluent에서 이 오프로딩 기술을 구현하였고, 올해는 Fluent에 네이티브 다중 GPU 솔버를 도입하여 GPU 기술 사용을 완전히 새로운 수준으로 끌어 올렸습니다. 네이티브 구현은 GPU에서 모든 솔버 기능을 제공하고 CPU와 GPU 간에 데이터를 교환하는 오버헤드를 방지하므로 오프로딩과 비교할 때 속도가 향상됩니다.
CFD용 GPU의 잠재력을 최대한 활용하려면 전체 코드가 GPU에 상주하여 실행되어야 합니다.
이 블로그 시리즈의 파트 1에서는 대형 자동차 외부 공기역학 시뮬레이션이 32배 속도 향상된 것을 강조했지만, 모든 사용자가 해당 크기의 모델을 시뮬레이션하는 것은 아니라는 점을 이해하고 있습니다. 이 블로그에서는 다공성 매체 및 복합열전달(CHT)을 포함하여 추가적인 물리 기능을 포함하는 소형 모델을 위한 GPU의 성능을 강조할 것입니다.
모든 규모의 CFD 시뮬레이션 가속화
512,000 셀에서 700만 셀에 이르기까지 이 블로그에 자세히 설명된 모델은 모두 GPU에서 해결할 때 상당한 성능 향상을 보여줍니다. 그리고 Fluent GPU 솔버가 랩톱 또는 워크스테이션 GPU를 사용하여 솔루션 시간을 크게 줄일 수 있기 때문에 상당한 성능 향상을 실현하기 위해 가장 고가인 서버 수준 GPU가 필요하지 않습니다. 여기에서 그치지 말고 네이티브 다중 GPU 솔버가 어떻게 속도 향상을 가져왔는지 계속 읽어보십시오.
- 흡기 시스템 8.32배
- 트랙션 인버터 8.6배
- 2개의 다른 열교환기 설계에서 15.47배 및 11배
다공성 필터를 통한 공기 흐름
자동차의 흡기 시스템은 공기를 흡입하고 필터를 통과시켜 이물질을 제거하고 깨끗한 공기를 엔진으로 보내는 데 사용됩니다. 이 710만 셀 시뮬레이션에서 필터는 1e+8m-2의 점성 저항과 2,500m-1의 관성 저항을 갖는 다공성 매체로 모델링됩니다. 공기는 0.08kg/s의 질량 유량으로 흡기 시스템에 유입됩니다.
하나의 NVIDIA A100 GPU에서 해결했을 때 8.32배 빨라진 흡기 시스템을 통해 간소화되었습니다.
이 모델을 해결하기 위해 4개의 다른 하드웨어 구성이 사용되었으며, 3개는 Intel® Xeon® Gold 6242 코어로, 1개는 NVIDIA A100 Tensor Core GPU로 구성되었습니다.
NVIDIA A100 GPU를 사용하면 32개의 Intel® Xeon® Gold 코어를 해결할 때보다 속도가 8.3배 향상되었습니다.
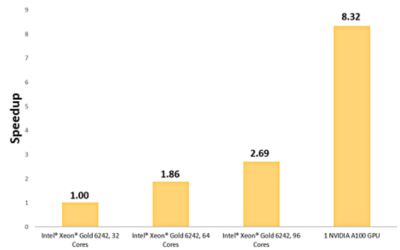
단일 NVIDIA A100 GPU를 사용하여 다공성 매체를 통한 공기 흐름을 시뮬레이션한 결과 32개의 Intel® Xeon® Gold 코어에 비해 8.3배 속도가 향상되었습니다.
하나의 NVIDIA A100 GPU에서 해결했을 때 8.6배 빨라진 CHT를 포함하는 트랙션 인버터 시뮬레이션입니다.
복합 열전달 모델링(CHT)을 사용한 열 관리
많은 산업 응용 분야에서 유체 흐름과 함께 열 효과를 고려하는 것이 중요합니다. 시스템의 열 거동을 정확하게 포착하려면 인접한 금속의 열 전도와 결합된 유체 내 열 전달이 중요합니다. 네이티브 GPU 솔버는 이러한 결합된 CHT 문제에 대해 엄청난 속도 향상을 보여줍니다.
아래에는 400만 셀 수냉식 트랙션 인버터, 140만 셀 루버핀 열 교환기 및 512,000셀 수직 장착 방열판 등 CHT를 포함하는 세 가지 열 시뮬레이션이 나와 있습니다.
수냉식 트랙션 인버터
트랙션 인버터는 고전압 배터리에서 직류(DC)를 가져와 이를 교류(AC)로 변환하여 전기 모터로 보냅니다. 열 관리는 트랙션 인버터의 안전과 수명을 모두 보장하는 데 매우 중요합니다.
위에 표시된 모델은 400W의 열 부하를 가진 4개의 절연 게이트 바이폴라 트랜지스터(IGBT)가 있는 400만 셀 수냉식 트랙션 인버터입니다. 냉각은 하우징을 0.5kg/s의 속도로 순환하는 25°C의 물에서 이루어지며, 대류 경계 조건을 사용하여 주변 공기에 대한 열 제거가 모델링됩니다.
하나의 NVIDIA A100 GPU에서 해결한 결과 32개의 Intel® Xeon® Gold 6242 코어에 비해 8.6배 속도가 향상되었습니다.
루버핀 열교환기

이 열 교환기 모델은 루버핀 열교환기를 통한 강제 대류를 사용합니다. 이 문제는 구리 튜브를 냉각시키기 위해 4m/s의 속도로 알루미늄 루버핀을 통해 흐르는 20°C의 공기로 구성됩니다.
기준을 설정하기 위해 8개의 Intel® Xeon® Gold 6242 코어에서 140만 셀 모델을 실행했습니다.
동일한 모델을 하나의 NVIDIA A100 GPU에서 실행하면 속도가 15.5배 향상되었습니다.
루버핀 열교환기의 온도 등고선은 하나의 NVIDIA A100에서 15.47배 더 빨리 해결되었습니다.
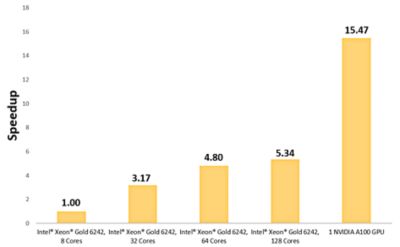
단일 GPU는 루버핀 열 교환기를 위한 15.47배 빠른 시뮬레이션 해결 속도를 제공함.
수직 장착 방열판
마지막 문제는 바닥이 76.85°C의 일정한 온도에서 유지되고 주변 온도가 16.85°C인 자유 대류 5핀 알루미늄 방열판으로 구성됩니다.
NVIDIA Quadro RTX 5000 GPU 1개가 탑재된 노트북에서 이 512,000셀 케이스를 해결한 결과 Intel® Core™ i7-11850H 코어 6개가 장착된 노트북과 비교할 때 속도가 11배 향상되었습니다.
NVIDIA Quadro RTX 5000과 같은 단일 노트북 GPU를 사용하는 경우에도 Fluent의 네이티브 다중 GPU 솔버를 사용하면 해결 시간을 크게 단축할 수 있습니다. 워크스테이션에서 유사한 그래픽 카드를 사용할 경우 훨씬 더 뛰어난 성능을 기대할 수 있습니다.
512,000셀 방열판 시뮬레이션은 하나의 NVIDIA Quadro RTX 5000 GPU에서 해결할 때 11배 빨라졌습니다.
GPU를 통한 CFD 시뮬레이션 혁신
이제 Fluent 사용자는 단일 GPU가 있는 노트북 또는 워크스테이션에서 실행하거나 다중 GPU 서버로 확장할 수 있는 능력과 유연성을 갖게 되었습니다. 이미 보유한 하드웨어를 활용하여 CFD 시뮬레이션을 생각했던 것보다 더 빠르게 수행할 수 있습니다.
Fluent의 네이티브 다중 GPU 솔버는 CUDA 드라이버 11.0 이상이 설치된 2016년 이후의 모든 NVIDIA 카드에서 실행됩니다.
Ansys는 시뮬레이션에 GPU 기술을 사용하는 선구자 역할을 해 왔으며, 이 새로운 솔버 기술을 통해 완전히 새로운 단계로 나아가고 있습니다. 네이티브 GPU 솔버의 모든 솔버 기능은 Fluent CPU 솔버와 동일한 이산화 및 수치적 방법으로 구축되어 그 어느 때보다 짧은 시간 내에 사용자가 기대하는 정확한 결과를 제공합니다.