























ANSYS BLOG
March 29, 2024
Simulation Helps GSK Bring Critical Medicines to Patients Faster
In the world of pharmaceuticals, most drugs can be broken up into two categories: small-molecule, chemically derived drugs and large-molecule biologics. Small-molecule drugs are compounds with low molecular weight and relatively simple chemical structures. These make up most of the drugs we have in our medicine cabinets, such as antihistamine and blood pressure medications. Biologics, however, consist of large, complex molecules such as proteins, carbohydrates, or nucleic acids that have a high molecular weight. As the name suggests, biologics are derived from living cells and make up hormones, vaccines, gene and cellular therapies, growth factors, insulin, and more.
Due to their simple structures, the pharmacokinetics and pharmacodynamics (what makes up the drug and how they interact with the body) of small-molecule drugs are more predictable than biologics, making manufacturing processes simpler and reproduction easier. Biologics’ extreme sensitivity to physical conditions make them notorious for their manufacturing difficulty and tend to have smaller yields. While small-molecule drugs might seem like the easier option to manufacture, both are necessary to prevent, treat, and cure the vast number of ailments humans face.

The differences between small- and large-molecule drugs.
Historically, small-molecule drugs have dominated the U.S. Food and Drug Administration (FDA) new drug approvals (NDAs). But as new innovations surface and patients’ medical needs grow, biologics are becoming more and more common. In 2023, 20 new biological license applications (BLAs) were approved by the FDA for indications including the treatment, prevention, or immunization of sickle cell disease, hemophilia A, Type 1 diabetes, Duchenne muscular dystrophy, and more.
But the process that goes into the creation of these drugs is far from simple. Drug development in general can take more than a decade and cost billions of dollars. From cell line selection to scaling the manufacturing processes, biologics are often riskier than their small-molecule counterparts. In an attempt to mitigate inconsistencies observed in the performance of their processes and cell lines between different bioreactor scales, the GSK Drug Substance Development (DSD) team turned to simulation.
Establishing Cell Lines
The generation of commercial, clonal cell lines expressing the biologic of interest is one of many important roles the GSK DSD team has. This involves engineering a cell to produce a specific, desired protein. Scientists transfer a gene encoding the desired protein into a cell, producing a pre-clonal pool of cell lines expressing the desired protein. The scientist then performs single cell cloning, generating multiple different cell lines all expressing the desired protein. These cell lines are then evaluated for growth, productivity, and quality in small scale production bioreactors, such as the Ambr15. The best performing cell line is selected, becoming the production line.
Scientists then transfer the production cell line to a bioreactor to establish a master cell bank (MCB) that creates genetically identical cells. The cells multiply for a few generations, creating hundreds of millions of identical copies. The cells are portioned into vials and frozen with liquid nitrogen. The deep freeze stops cell growth so it can be thawed and used later.
A working cell bank (WCB) is then created by thawing one of the vials containing the MCB cells, allowing the cells to multiply in a bioreactor, and are then frozen again. Each new production run starts by thawing a vial from the WCB.
Because these cells are intended for human use, stable longevity is key, as the quality and safety need to be guaranteed throughout the entire life cycle of a drug. If the cell line does not create the appropriate quality in a stable and reproducible manner, the whole manufacturing process is at risk.
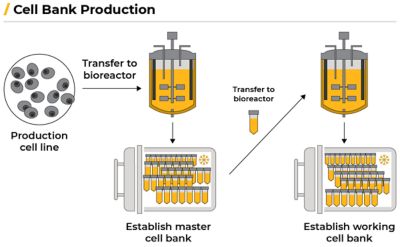
A biomanufacturing workflow. Adapted from: Burke, Emily. “Biomanufacturing: How Biologics Are Made.” Biotech Primer Inc., Biotech Primer, Inc., 31 Aug. 2023, biotechprimer.com/how-biologics-are-made.
Scaling Up Biopharmaceutical Production
In addition to establishing cells lines, the GSK DSD team is responsible for the development of scalable, robust, and efficient upstream and downstream processes and the transfer of those processes to commercial manufacturing scale.
They select their cell lines and start them in a 15-milliliter bioreactor, but eventually these need to be scaled up to 2,000-liter bioreactors. Biological processes scale unpredictably; not only must differences between the bioreactor sizes be accounted for, but the cells’ sensitivity to changes must also be taken into consideration.
While the DSD team uses predictive modeling to predict production processes, it is still nearly impossible to account for every single parameter. Cell line and bioreactor conditions need to be tightly controlled or the cell lines could die, which would require the DSD team to start production over again.
Predictive models developed at small scale require additional (often expensive) testing to calibrate for larger scales, and detailed vessel models may require proprietary third-party data. The DSD team also needed their solution to transfer code from the cell culture bioreactor model from gPROMS, the software on which it was developed.
The DSD team used Ansys Fluent to model the hydrodynamic profiles in GSK’s bioreactors and in different conditions using computational fluid dynamics (CFD). The CFD-based investigation was critical for achieving better scale-down models of the large-scale bioreactors, therefore enabling less expensive and more efficient experimentation for progressing biopharmaceutical assets through the pipeline.
“Fundamentally, it's a lot easier to use CFD combined metabolic models to look at how our small-scale data will apply in the larger scale than it is to try and really mimic 2000-liter conditions exactly in the small scales,” says Luisa Attfield, associate data scientist at GSK.

A comparison of 15-milliter to 2000-liter CFD bioreactor models in Ansys Fluent
The DSD team used the CFD models to create static reduced-order models (ROMs) in Ansys Twin Builder digital twin simulation software to predict selected outputs at each scale, primarily the mass transfer coefficient (kLa). The ROMs acted as virtual sensors that provided inputs to the cell compartment model, created with the Modelica language.
“We know that cell growth is dependent on different things like oxygen concentration,” said Attfield. “So within Twin Builder, what we're looking at is dissolved oxygen. Any gradients of dissolved oxygen across the large bioreactor scales — oxygen transfer being the mass transfer coefficient — and combining that oxygen transfer into the metabolic models to see how the cells will behave and what we expect the local environment to be like.”
The ROMs and cell compartment model were linked in a system model created in Twin Builder and exported as a digital twin runtime. Ansys Twin Deployer was used to convert these into a scaffolding Python command line application that connected to an industrial Internet of Things (IIoT) platform. It was important to transfer the code for the cell culture bioreactor model from gPROMS to Modelica to enable the deployment of the L1 digital twin. For that reason, Ansys engineers developed a Python code that translates the gPROMS code to a language that is compatible with Fluent. This is critical because it enables a seamless translation of future changes that GSK might apply in the gPROMS model to the Modelica language.
“We definitely benefited from this collaboration — not just the software, but the help and support that we had from Ansys,” said Pavlos Kotidis, digital and data analytics leader at GSK. “There were a lot of conversations between us and Ansys to upskill our team in the CFD space. Otherwise, it would have taken us much longer to get the project going.”
Learn how Ansys Fluent and Ansys Twin Builder can help with your drug manufacturing processes.